
Blog
L’essor de la spectrohéliographie amateur
21 May 2026
Tags: solex jsolex spectroheliographie solaire astronomie histoire sunscan shg700
De l’invention professionnelle (1868) à la communauté Sol’Ex contemporaine.
Ce billet est aussi disponible en PDF. Source ouverte aux contributions sur GitHub.
La spectrohéliographie amateur est l’imagerie solaire monochromatique pratiquée par des astronomes non professionnels. La technique consiste à reconstruire une image du Soleil dans une raie spectrale précise, en balayant son disque avec la fente d’entrée d’un spectrographe. Pendant près d’un siècle, l’encombrement et le coût des instruments la réservent aux grands observatoires. Elle devient accessible aux amateurs dans les années 1960, avec la version visuelle de l’instrument, le spectrohélioscope. Deux ruptures suivent : les capteurs numériques et l’informatique au tournant des années 2000, puis les instruments compacts à impression 3D diffusés à partir de 2020, dont le plus connu est le Sol’Ex de Christian Buil. Au début des années 2020, la discipline s’est dotée d’une communauté internationale, de logiciels libres, de bases d’images et de collaborations « pro-am » intégrées au suivi scientifique du Soleil. Cet article retrace cette trajectoire, de l’invention professionnelle de l’instrument jusqu’à la production scientifique amateur contemporaine.
|
Note
|
Transparence. L’auteur est le développeur de JSol’Ex et de SpectroSolHub, deux projets décrits dans ce document, et un contributeur actif de la communauté présentée. Cette histoire a été rédigée avec un souci de neutralité (en particulier dans la comparaison entre logiciels), les faits ont été vérifiés et les sources primaires privilégiées. Le lecteur est invité à lire les passages concernant l’auteur avec ce recul. Il s’agit d’une synthèse compilée par un membre de la communauté, non d’une étude académique. |
Contexte : l’invention professionnelle (1868-1932)
L’idée d’observer le Soleil à travers une raie isolée du spectre remonte à 1868. Cette année-là, Jules Janssen et Joseph Norman Lockyer démontrent indépendamment que les protubérances solaires peuvent s’observer en dehors d’une éclipse : il suffit de placer la fente d’un spectroscope sur le limbe et de centrer l’instrument sur les raies brillantes de l’hydrogène [1]. Cette technique dite « de la fente large » reste limitée à l’observation visuelle de zones restreintes du limbe.
Le spectrohéliographe proprement dit produit une image bidimensionnelle complète du disque solaire dans une raie choisie, par balayage et reconstitution photographique. Il est inventé indépendamment au début des années 1890 par l’Américain George Ellery Hale et le Français Henri Deslandres [2]. Hale construit son premier instrument à l’observatoire Kenwood de Chicago. Deslandres entre à l’Observatoire de Paris en 1889 pour y développer la spectroscopie et obtient en 1892, à partir des idées de Janssen, les premières images monochromatiques de la chromosphère dans les raies H et K du calcium ionisé [2] [3]. En 1897, il installe à Meudon un spectrohéliographe alimenté par sidérostat polaire, et en 1909 fait construire le bâtiment du grand spectrohéliographe qui demeure en service jusqu’au XXIe siècle [3]. Hale obtient quant à lui en 1908, depuis le Mont Wilson, les premières images dans la raie Hα [1].
Deslandres conçoit en réalité dès l’origine deux instruments aux fonctions distinctes [4]. Le premier, le spectrohéliographe des formes, balaie le disque en continu pour produire l’image monochromatique décrite plus haut. Le second, le spectrohéliographe des vitesses, procède par pas discrets d’une vingtaine de secondes d’arc et enregistre à chaque pas le profil complet de la raie. Il mesure des vitesses radiales et donne ainsi accès à la dynamique de la photosphère. Cette seconde voie reste active à Meudon jusqu’en 1939. Interrompue par la guerre, elle n’est reprise qu’en 2017, avec un capteur sCMOS rapide qui retrouve, en continu cette fois, le profil de raie en tout point du disque [4].
L’écart de taille entre le grand spectrohéliographe de Meudon et un instrument amateur moderne s’explique par les contraintes du détecteur de l’époque [4]. Conçu pour des plaques photographiques 13 × 18 cm, l’instrument devait agrandir l’image du Soleil à un diamètre de 86 mm au plan focal. Les capteurs CMOS d’aujourd’hui imposent à l’inverse une réduction de focale pour ramener le disque à moins de 11 mm sur le détecteur. À cahier des charges équivalent, un grand spectrohéliographe professionnel construit aujourd’hui serait sensiblement plus compact.
Le spectrohélioscope est inventé par Hale en 1924. C’est la version visuelle de l’instrument : deux fentes oscillantes synchronisées y créent, par persistance rétinienne, une image monochromatique observable directement à l’œil. Il en publie la description et les usages dans quatre articles parus dans l'Astrophysical Journal entre 1929 et 1931 [5]. En 1932, Robert R. McMath, à l’observatoire McMath-Hulbert (Michigan), étend le procédé en y adjoignant une caméra cinématographique : son spectroheliokinematograph livre les premiers films de protubérances solaires, et lui vaut, avec ses collaborateurs, la médaille John Price Wetherill [6] [7].
C’est dans la foulée de cette percée que Hale invite explicitement les astronomes non professionnels à participer au suivi du Soleil, qu’il conçoit comme un laboratoire de recherche. La spectrohéliographie amateur prend dès lors sa source dans cette invitation, mais devra attendre plus de trente ans pour devenir techniquement réalisable hors d’une grande institution [1].
Premiers spectrohélioscopes amateurs (1938-1990)
Avant la Seconde Guerre mondiale, deux Britanniques construisent les premiers spectrohélioscopes purement amateurs, en suivant l’architecture de Hale à longue focale et installation fixe : F. J. Sellers en 1938, qui invente un synthétiseur de fentes oscillantes original [8], puis M. A. Ellison en 1940 [9]. Tous deux publient leurs travaux dans le Journal of the British Astronomical Association (BAA). En 1958 et 1959, les premiers instruments amateurs apparaissent aux États-Unis avec B. C. Parmenter (Spokane) et W. J. Semerau (New York), ce dernier décrivant son SHS dans plusieurs articles de Sky & Telescope entre 1959 et 1962 [10].
Le facteur limitant principal pour les amateurs est alors le réseau de diffraction : un réseau original, gravé mécaniquement, coûte plus de 1 000 dollars de l’époque [10]. La donne change en 1957 avec la commercialisation par Bausch & Lomb de réseaux répliqués par dépôt résineux, conservant 90 % de la résolution théorique mais à environ un dixième du prix [10]. Les réseaux holographiques répliqués, apparus en 1963, prolongent cette évolution. Sans réseau abordable, rien de la spectrohéliographie amateur qui suit n’aurait été possible.
Fredrick N. Veio (1962-2009)
Une figure centrale de la spectrohéliographie amateur du XXe siècle est l’Américain Fredrick Nall Veio (Californie, 1930-2022) [11]. Construisant en 1962-1964 un spectrohélioscope compact (lentille de télescope 60 mm / 2,7 m de focale, spectroscope Littrow 1,9 m, réseau Bausch & Lomb 1200 tr/mm) pour environ 300 dollars, il en publie le plan dans Sky & Telescope de janvier 1969, puis dans le Journal of the BAA en 1975 [10] [12]. Sa principale innovation est un synthétiseur à disque de verre tournant de 100 mm de diamètre, peint en noir et percé de 24 fentes de 125 µm définissant une bande passante de 0,5 Å en Hα, beaucoup plus simple à fabriquer que les fentes oscillantes de Hale [10].
À partir de 1972, Veio diffuse une brochure d’auto-construction (initialement 56 pages, étendue à 120 pages vers 2000) dont plus de 2 000 exemplaires circulent à travers le monde [10]. Pendant plus de trente ans (1967-1998), il entretient une correspondance estimée à 9 000 lettres avec des amateurs étrangers, travail patient d’évangélisation que le passage à Internet (1999, création d’un forum Yahoo dédié) accélère ensuite considérablement [10]. Toshio Ohnishi (Japon) puis Mike Rushford (Californie) et J. Christopher Westland (Hong Kong) hébergent successivement la version libre et numérique du livre [10].
Veio recense, dans ses « histoires de la spectrohélioscopie amateur » de 2009-2010, l’apparition régulière de nouvelles constructions à travers les années 1970-1990 : Theodore van Poecke (Pays-Bas, 1971), Donald Mruk (Massachusetts, 1971, à 17 ans), Achim Gruenberg et Ulrich Fritz (Allemagne, 1975), Brian G. W. Manning (Angleterre, 1975, inventeur du synthétiseur Manning sans vibrations et premier amateur à fabriquer un réseau original de qualité), Toshio Ohnishi (Japon, 1975, inventeur vers 1990 du synthétiseur Ohnishi, à fentes oscillantes à extrémités repliées), Heinrich Beeker (Allemagne, 1980, conception originale de cœlostat), Jeffrey Young (Californie, 1982, miroir oscillant remplaçant les prismes d’Anderson), Henry Hatfield (Angleterre, 1985), Gote Flodqvist (Suède, 1994), Rogerio Marcon (Brésil, 1992) [10]. Le premier amateur européen à construire une version compacte et transportable est van Poecke, qui hérite des optiques d’origine de Veio [10].
Premiers exploits scientifiques (1975-2006)
Plusieurs résultats scientifiquement significatifs sont obtenus par des amateurs dans cette période. Vers 1975, Brian Manning réalise l’une des premières observations amateurs documentées du décalage Doppler des raies du sodium sur les bords du limbe solaire, démonstration directe de la rotation différentielle, avec un réseau utilisé au cinquième ordre et un film Kodak 2415 à grain fin [10] [13]. En 1999, Fredrick Veio et Leonard Higgins (Napa, Californie) observent visuellement, pour la première fois à notre connaissance, l’effet Zeeman dans une tache solaire avec un spectrohélioscope amateur. Les identifications spectrales sont confirmées en 2002-2003 [10]. L’article correspondant paraît dans le Journal of the BAA en février 2006, à notre connaissance la première publication scientifique d’amateurs sur l’effet Zeeman solaire [14].
La révolution numérique (1990-2016)
Le passage de l’imagerie argentique à la détection électronique modifie en profondeur la pratique. Deux voies coexistent à la fin des années 1990 : la barrette CCD linéaire et la webcam.
L’approche linéaire : Philippe Rousselle
Le Français Philippe Rousselle (Metz) réalise ses premiers spectrohéliogrammes au tout début des années 1990 (vers 1992, un siècle après les premières images de Deslandres) [15]. Son montage initial associe une lunette, un capteur CCD linéaire Thomson et un micro-ordinateur Atari 520. Il pointe d’abord le Soleil depuis la fenêtre de son appartement, avant d’installer l’instrument dans son garage. L’objectif lui est vendu par Fred Veio, avec qui il correspond plusieurs années. Le principe est de laisser l’image du Soleil dériver devant la fente d’entrée : un ordinateur enregistre chaque ligne au passage et reconstitue l’image complète. Il est, selon Veio, le premier amateur à utiliser un détecteur linéaire, et atteint une résolution de l’ordre de 2″ sur le disque solaire [10]. Rousselle développe aussi ses propres logiciels de traitement (images 8 bits, cartes Doppler, mesure de la position des structures, cartes synoptiques) [15]. Son site web, ouvert vers 2001-2002, sert de plate-forme de documentation et d’archive solaire continue jusqu’au début des années 2020, et héberge aussi la version libre du livre de Veio ainsi qu’un atlas des longueurs d’onde de Charlotte Moore [16]. Plusieurs amateurs lui emboîtent le pas et construisent leur propre instrument, dont Daniel Defourneau, les Rondi et Jean-Jacques Poupeau [15]. En 2003, Rousselle confirme avec son instrument les détections de l’effet Zeeman et du décalage Doppler signalées par Veio [10].
L’approche webcam et logicielle : Daniel Defourneau et Christian Buil
Au printemps 2002, le Français Daniel Defourneau (Le Pin, près de Paris, spécialiste informatique appliquée à la spectroscopie infrarouge sous vide) imagine une approche radicalement différente : il utilise une webcam classique pour filmer en continu le spectre du Soleil, laissant le disque dériver naturellement devant la fente d’un petit spectrographe fixe [17]. Il écrit en Visual Basic un logiciel, SpecHelio (méthode dite « 2D »), qui sélectionne une colonne unique de pixels centrée sur la raie choisie et la concatène image par image pour reconstituer le disque entier [17]. Son spectrohéliographe « de poche » (lunette de 60 mm en collimateur, téléobjectif de 200 mm, réseau, total environ 6 kg, coût inférieur à 200 €) tient sur une planche de bois et fonctionne sans monture motorisée [17]. Sa première image est présentée le 26 juin 2002 sur la liste de diffusion Astrocam (message n° 31161) [17]. Il publie le logiciel sur son site « cieldelabrie », et démontre en octobre 2009, selon les histoires de Veio, la première observation amateur d’ondes de Moreton ainsi que la première image Doppler colorée du limbe [10].
Quelques mois après Defourneau, Christian Buil lit la description de la méthode, l’expérimente avec succès, l’améliore et l’intègre à son logiciel généraliste IRIS [10] [17]. La diffusion d’IRIS, abondamment documenté, contribue à populariser la technique en France et en Europe. Alex Canicio (sud de la France) écrit ensuite un logiciel plus rapide (AstroSnap), puis José Ribeiro en 2004 abaisse encore le temps de traitement d’environ dix minutes à deux minutes par image [10]. La méthode webcam + logiciel devient alors le standard amateur : tout au long des années 2010, plusieurs amateurs poursuivent la voie ouverte par Defourneau en construisant leurs propres spectrohéliographes numériques, jusqu’à la diffusion de Sol’Ex.
Magnétogrammes amateurs : André et Sylvain Rondi
Le tandem père-fils André et Sylvain Rondi, en 2005-2006, franchit une nouvelle étape. À partir d’un spectrohéliographe compact à webcam et de polariseurs, ils acquièrent séparément les images d’une région de tache solaire en lumière polarisée droite et gauche, les empilent par traitement IRIS, puis les combinent pour produire ce qui constitue, à notre connaissance, le premier magnétogramme solaire amateur (été 2006), avec une résolution d’environ 6″ [10] [18]. La démarche reprend la méthodologie professionnelle de l’effet Zeeman longitudinal et démontre qu’avec un instrument compact, une discipline d’acquisition et une chaîne logicielle adaptée, l’amateur peut accéder à des observables qui étaient jusqu’alors réservés aux observatoires solaires spécialisés. Le site des Rondi conserve la documentation complète de ces travaux et un historique illustré de la spectrohéliographie [18].
L’état de l’art en 2016 : Ken Harrison, Imaging Sunlight
L’Australien et britannique d’origine Ken M. Harrison publie en 2016, dans la collection Patrick Moore Practical Astronomy Series chez Springer, Imaging Sunlight Using a Digital Spectroheliograph, premier ouvrage de référence consacré au spectrohéliographe numérique amateur [19]. Le livre couvre la conception optique, la construction mécanique, les logiciels disponibles à l’époque (Virtual Dub, Image J, BASS Project, SpecHelioBas, et SliM de Wah-Heung Yuen), ainsi qu’un panorama des instruments amateurs alors actifs aux États-Unis, au Royaume-Uni, en France, en Italie, en Chine et en Australie [19]. Ses derniers chapitres retracent une histoire raisonnée du domaine, de Hale et Deslandres jusqu’à Veio. L’ouvrage paraît juste avant que la pratique ne se diffuse largement, et en fixe l’état de l’art technique.
La rupture Sol’Ex (2020-)
Christian Buil et la conception de Sol’Ex

Fin 2020, Christian Buil conçoit le Sol’Ex (Solar Explorer) [20]. Ingénieur retraité du CNES et figure de l’astronomie amateur française depuis les années 1990, il est l’auteur d’IRIS, d’ISIS et d’une famille de spectrographes commerciaux développés avec Shelyak Instruments (LHIRES III, eShel, Alpy 600). L’idée directrice est de mettre à profit deux ruptures technologiques récentes : les imprimantes 3D grand public, qui permettent de fabriquer chez soi des pièces mécaniques précises à coût quasi nul, et les caméras CMOS monochromes très rapides (ASI290 mini et équivalents), capables de saisir des spectres à plus de 100 images par seconde [20].
Sol’Ex se présente comme un parallélépipède en PLA imprimé en 3D, de 500 g, contenant une fente de 10 µm, un doublet collimateur, un réseau holographique de 2 400 traits/mm, un doublet imageur et la caméra [20]. Il s’installe à l’arrière d’une lunette astronomique courante (40 à 100 mm d’ouverture, focale ≤ 480 mm pour imager le disque entier), précédée d’un filtre énergétique (Baader AstroSolar ou prisme de Herschel). L’acquisition repose sur le déplacement contrôlé du télescope en ascension droite (8 à 16× la vitesse sidérale), enregistré sous forme de fichier vidéo SER, puis reconstruit ligne à ligne par logiciel. En enregistrant le profil complet de la raie en chaque colonne, Sol’Ex et ses dérivés numériques renouent, près d’un siècle plus tard, avec le spectrohéliographe des vitesses de Deslandres, interrompu en 1939 et repris à Meudon en 2017 seulement [4]. Le kit optique est diffusé en commerce par Shelyak Instruments [21], les fichiers STL d’impression 3D et la documentation sont mis en ligne sous une forme didactique très soignée [20]. Une variante stellaire, Star’Ex, dérive du même boîtier par échange de quelques pièces optiques et permet la spectrographie d’étoiles, de comètes, de nébuleuses et de quasars [20].
L’instrument est présenté officiellement en 2021 lors des journées ProAm de la Société Française d’Astronomie et d’Astrophysique (SF2A) [22]. En quelques mois, plus de 150 amateurs à travers le monde se sont lancés dans la construction [23], et au milieu des années 2020 la communauté internationale dépasse plusieurs milliers d’utilisateurs.
INTI et INTI Partner : Valérie Desnoux
Le traitement des fichiers SER produits par Sol’Ex est confié dès l’origine à Valérie Desnoux, collaboratrice de longue date de Christian Buil (auteure du logiciel d’analyse spectrale VSPEC) et actrice de longue date du milieu amateur français. Elle conçoit et développe en Python INTI, logiciel open source dédié à Sol’Ex et recommandé par Christian Buil, qui automatise en un clic l’ensemble de la chaîne : détection de la raie sombre la plus marquée dans la vidéo, modélisation par un polynôme, extraction colonne par colonne, correction du « smile » et du « tilt », reconstruction de l’ellipse solaire, correction géométrique en disque circulaire, ajustement d’échelle et orientation [24]. INTI fixe les conventions de fichiers (FITS 16 bits, JPEG 8 bits, orientation nord-haut/est-gauche) qui rendent les images amateurs compatibles avec les bases de données professionnelles, et fut le premier logiciel adopté pour la soumission au projet SOLAP/BASS2000 [25].
Valérie Desnoux développe également INTI Partner, boîte à outils complémentaire qui regroupe plusieurs applications : visualiseur d’images et de fichiers SER, sélecteur des meilleures images par comparaison par paires, module de stacking avec correction des distorsions, animation, INTI Mosaic (composition de mosaïques fondée sur la méthode multirésolution de Burt & Adelson de 1983) [26], grille de coordonnées de Stonyhurst, et planisphère synoptique sur rotation solaire [27]. INTI Partner accepte des images produites par d’autres logiciels (JSol’Ex, SUNSCAN) ou d’autres spectrohéliographes que Sol’Ex [27].
Le fork anglophone : Douglas Smith
À partir de 2021, le Britannique Douglas Smith (Londres) et son fils étudiant publient un fork anglophone du code source originel de Valérie Desnoux (Vdesnoux/Solex_ser_recon) sous le nom Solex_ser_recon_EN, hébergé sur GitHub sous le pseudonyme « thelondonsmiths » [28]. Le fork apporte une interface en anglais, une plus grande flexibilité dans le basculement entre corrections géométriques automatiques et manuelles, un contrôle individuel des fichiers sauvegardés, et une accélération significative du traitement (typiquement 5× à 10× selon les données, grâce au multithread) [28] [29]. Le logiciel s’enrichit ensuite d’un mode batch, de traductions multilingues, d’un exécutable Windows autonome et d’un outil Pixel Offset Live permettant d’identifier des raies spectrales par rapport à une raie d’ancrage avec calcul automatique de la dispersion [30]. Le projet est largement diffusé sur SolarChat et Cloudy Nights, où Douglas Smith publie régulièrement images, présentations et tutoriels [31]. Une variante expérimentale supportant les fichiers AVI, Digital_SHG, en est dérivée par Matt Considine [32].
JSol’Ex : Cédric Champeau

L’ingénieur logiciel français Cédric Champeau, spécialisé dans le logiciel open source, découvre la spectrohéliographie en février 2023 à l’occasion d’une « Nuit au Sommet » à l’Observatoire du Pic du Midi de Bigorre. Confronté au coût prohibitif des filtres et étalons solaires traditionnels, il s’oriente vers Sol’Ex, mais souhaite comprendre par lui-même la mécanique de reconstruction d’image. Pour relever ce défi pédagogique personnel, il développe à partir de 2023 JSol’Ex, une implémentation indépendante de la chaîne de reconstruction écrite en Java, publiée sous licence Apache 2 dans le projet open source astro4j [33].
JSol’Ex a été conçu dès l’origine dans une intention didactique et avec un fort souci de facilité d’utilisation, prolongeant la démarche pédagogique de son auteur : le logiciel propose des fonctions qui rendent visibles les étapes de la reconstruction de l’image et aident l’utilisateur à interpréter les images obtenues : quelle raie est observée, à quelle couche de l’atmosphère solaire elle correspond, ou ce que traduit un décalage Doppler. Il rend surtout accessibles en quelques clics des traitements jusque-là réservés aux utilisateurs avancés, comme l’extraction de la raie de l’hélium ou l’imagerie de la couronne solaire. Au-delà de cette accessibilité, JSol’Ex est le premier logiciel SHG à proposer un langage de scripts intégré (ImageMath, complété par Python), avec dépôts de scripts communautaires, permettant de générer des images personnalisées : continuum, Doppler, animations [33]. Il offre également le stacking et la composition de mosaïques [34], la correction des bords dentelés, l’identification automatique des régions actives et la détection d’éruptions, ainsi que des outils d’analyse avancés : la détection des bombes d’Ellerman [35], la mesure de la rotation différentielle solaire [36] et une visualisation 3D du cube spectral [37].

Porté par cette dynamique d’innovation, le logiciel devient progressivement très populaire au sein de la communauté Sol’Ex, et trouve également des utilisateurs sur d’autres spectrohéliographes, notamment le ML Astro SHG 700. Cette popularité croissante débouche en septembre 2025 sur une reconnaissance institutionnelle : JSol’Ex devient officiellement, aux côtés d’INTI, un outil de soumission accepté pour la base BASS2000 de l’Observatoire de Paris-Meudon [38]. Parallèlement, l’algorithme de détection des bombes d’Ellerman est cité dans la littérature professionnelle [39] et le logiciel est utilisé pour la production de l'Atlas of Spectroheliograms from 3641 to 6600 Å de Váradi Nagy et Pietrow (2025) [40]. JSol’Ex sert donc désormais à exploiter scientifiquement les données amateurs.
SpectroSolHub
En 2026, Cédric Champeau lance SpectroSolHub, plateforme communautaire dédiée au partage et à la discussion des images de spectrohéliographie solaire produites par la communauté Sol’Ex et SHG 700 [41]. Le site héberge galeries, classements, discussions, dépôts de scripts JSol’Ex et flux d’activité. Il permet notamment de générer des animations du Soleil sur plusieurs jours, en agrégeant les observations de nombreux utilisateurs. JSol’Ex et INTI Partner intègrent tous deux une fonction de publication directe vers cette plateforme.
Concurrence et diversification du matériel
Le succès de Sol’Ex a entraîné, en quelques années, l’émergence d’une gamme d’instruments commerciaux dérivés ou concurrents. Il n’est pas impossible que la qualité et le contraste des images amateurs obtenues avec un SHG soient à l’origine du renouveau des instruments commerciaux à base d’étalons, comme la lunette SkyWatcher Heliostar. En 2024-2025, le Vietnamien Nguyen Trong Minh (Hanoï, ingénieur civil) commercialise via la marque ML Astro le SHG 700, spectrohéliographe entièrement assemblé et calibré en usine, doté de micromètres de précision sur les principaux axes optiques, conçu pour des lunettes de focale ≤ 700 mm et présenté comme une version plus robuste et plus directement opérationnelle [42] [43]. Son lancement est suivi d’une diffusion rapide à l’international. Comme pour Sol’Ex, le pouvoir de résolution spectrale dépend principalement de la configuration optique (ouverture et focale de la lunette, largeur de fente) plus que de l’instrument lui-même. Les deux spectrohéliographes offrent des performances du même ordre [40].
Azur3DPrint, partenaire commercial du projet Sol’Ex, propose des kits mécaniques pré-imprimés et pré-assemblés. Shelyak Instruments distribue le kit optique de référence (fente, réseau, doublets) [21]. La motorisation du réseau, qui permet de basculer d’une raie spectrale à l’autre depuis un smartphone, fait l’objet de plusieurs projets open source (par exemple celui de Jean Brunet et Stéphane Ferier sur GitHub) [44].
SUNSCAN et l’association STAROS
L’étape suivante, en 2024-2025, est franchie avec SUNSCAN, instrument autonome développé par l’équipe STAROS Projects (Guillaume Bertrand, Christian Buil, Valérie Desnoux, Olivier Garde, Matthieu Le Lain) [45]. SUNSCAN intègre dans un unique boîtier la lunette, le spectrohéliographe, une caméra couleur miniature, un mini-ordinateur Raspberry Pi et une batterie. Il est piloté par smartphone ou tablette en Wi-Fi et fournit des images de la chromosphère solaire en quelques minutes, sans monture motorisée ni connaissances préalables [45] [46]. Présenté aux Rencontres du Ciel et de l’Espace (RCE) en novembre 2024, l’instrument vise en priorité l’éducation : clubs, écoles, animations grand public [47]. Il est diffusé sous licence open source, avec une application mobile dédiée (iOS/Android) [48]. En novembre 2025, SUNSCAN vaut à l’équipe STAROS le premier prix du Grand Prix triennal pour l’innovation instrumentale amateur de la Société astronomique de France (SAF) [49].

L’association à but non lucratif STAROS fédère par ailleurs l’ensemble de l’écosystème (Sol’Ex, Star’Ex, SUNSCAN, INTI), coordonne le financement participatif et structure la communauté en interface avec les chercheurs [45].
La collaboration pro-amateur (2023-)
SOLAP et BASS2000
Le 7 février 2023, l’Observatoire de Paris-Meudon lance avec Christian Buil le projet SOLAP, collaboration formalisée entre astronomes professionnels et amateurs équipés de Sol’Ex [25]. L’objectif est de prolonger et d’enrichir la base de données solaire BASS2000, qui archive depuis Deslandres plus de 100 000 images monochromatiques du Soleil prises à Meudon en Hα et Ca II K, couvrant plus de dix cycles solaires [50]. La couverture géographique des amateurs (plusieurs dizaines de stations à travers le monde) compense les aléas météorologiques d’un site unique : la chromosphère peut ainsi être suivie quotidiennement, et souvent plusieurs fois par jour.
Le protocole, publié en 2023 par Jean-Marie Malherbe, Florence Cornu et Isabelle Bualé (LESIA), impose le traitement par INTI et le format FITS 16 bits avec orientation normalisée [25]. Au printemps 2025, SOLAP compte 41 contributeurs réguliers et plus de 6 000 images ont été archivées dans BASS2000 [50]. Le projet est coordonné à Meudon par Milan Maksimovic, et l’Observatoire de Paris a organisé en mai 2025 une rencontre conviviale entre chercheurs et amateurs SOLAP au LIRA (Service Solaire), incluant une visite du spectrohéliographe historique [50].
Production scientifique amateur
Des publications scientifiques s’appuient désormais directement sur des données acquises par Sol’Ex et SHG 700. Buil, Malherbe et Maksimovic publient en 2023 dans Photoniques un article de synthèse sur Sol’Ex et l’imagerie monochromatique solaire dans le cadre de la collaboration pro-am [51]. En 2025, Pál Váradi Nagy et A. G. M. Pietrow (Leibniz-Institut für Astrophysik Potsdam) publient un atlas de spectrohéliogrammes de 3641 à 6600 Å entièrement réalisé avec un Sol’Ex et un ML Astro SHG 700 pendant le maximum solaire 2025, à une résolution spectrale R = 20 000 – 40 000 et une résolution spatiale moyenne de 2,5″ [40]. La même année, l’article de Faryad et al. sur la détection automatique des bombes d’Ellerman cite JSol’Ex parmi les pipelines de détection contemporains [39]. Des amateurs équipés produisent donc des jeux de données assez cohérents pour servir de référence à la recherche professionnelle, notamment pour les comparaisons Soleil/étoiles utiles à la recherche d’exoplanètes.
Vue d’ensemble : structure et dynamique de la pratique contemporaine
À la fin des années 2020, la spectrohéliographie amateur articule plusieurs composantes :
-
Matériel : Sol’Ex (auto-construit, imprimé 3D, ~600 €), ML Astro SHG 700 (clé en main, robuste), SUNSCAN (tout-en-un, éducatif), auxquels s’ajoutent un nombre encore important d’instruments artisanaux à plus longue focale construits dans la lignée Veio/Manning par des amateurs chevronnés.
-
Logiciels de reconstruction : INTI (Desnoux, Python, référence pour la chaîne BASS2000), Solex_ser_recon_EN (fork anglophone de D. Smith, multithread, multilingue, exécutable Windows), JSol’Ex (Champeau, Java, fonctions analytiques avancées, également accepté pour la soumission à BASS2000).
-
Logiciels de post-traitement et de partage : INTI Partner (Desnoux, mosaïques, animations, planisphère synoptique), SpectroSolHub (Champeau, plateforme communautaire).
-
Acquisition : SharpCap et FireCapture (commerciaux), captures au format SER.
-
Communautés : liste de diffusion Solex-project sur groups.io, serveur Discord JSol’Ex, sous-forum dédié sur Astrosurf, communauté SHS historique, fils dédiés sur Cloudy Nights et SolarChat. Les Rencontres du Ciel et de l’Espace (Paris) et les rencontres d’observateurs solaires servent de points de rencontre annuels.
-
Données : base BASS2000 de l’Observatoire de Paris-Meudon, hébergement gratuit d’archives personnelles sur Astrosurf, dépôts d’atlas sur arXiv et sites institutionnels.
-
Ouvrages de référence : The Spectrohelioscope de Veio (1972, étendu en 2000, libre), Imaging Sunlight de Harrison (Springer, 2016, ISBN 978-3-319-24872-1), Guide de l’observation solaire avec un spectrohéliographe de Christian Buil et Valérie Desnoux (EDP Sciences, 2026, ISBN 978-2-7598-3931-5), Astronomie solaire de Christian Viladrich et coll. (Axilone, ISBN 979-10-92974-06-5).
Chronologie
Principaux jalons de l’histoire de la spectrohéliographie, professionnelle puis amateur :
-
1868 : Janssen et Lockyer observent les protubérances solaires en dehors d’une éclipse.
-
v. 1890 : invention indépendante du spectrohéliographe par George Ellery Hale et Henri Deslandres.
-
1892 : Deslandres obtient les premières images monochromatiques de la chromosphère.
-
1908-1909 : premières images en Hα par Hale (Mont Wilson). Grand spectrohéliographe de Meudon.
-
1924 : Hale invente le spectrohélioscope.
-
1932 : McMath filme les protubérances solaires (spectroheliokinematograph).
-
1938-1940 : premiers spectrohélioscopes amateurs en Angleterre (Sellers, puis Ellison).
-
1957 : commercialisation des réseaux de diffraction répliqués par Bausch & Lomb.
-
1962-1972 : Fredrick Veio construit un spectrohélioscope compact et diffuse sa brochure d’auto-construction.
-
1975 : Brian Manning : observation amateur du décalage Doppler du sodium.
-
v. 1992 : Philippe Rousselle réalise les premiers spectrohéliogrammes amateurs au détecteur linéaire (CCD Thomson, Atari 520).
-
2002 : Daniel Defourneau : méthode webcam + logiciel, première image le 26 juin.
-
2005-2006 : André et Sylvain Rondi : premier magnétogramme solaire amateur.
-
2006 : Veio et Higgins publient leur observation de l’effet Zeeman au spectrohélioscope (Journal of the BAA).
-
2016 : Ken Harrison publie Imaging Sunlight (Springer).
-
2020 : Christian Buil conçoit le Sol’Ex.
-
2021 : présentation de Sol’Ex aux journées ProAm SF2A. Fork Solex_ser_recon_EN (D. Smith).
-
2023 : lancement du projet SOLAP (7 février). Premières versions de JSol’Ex (Cédric Champeau).
-
2024 : commercialisation du SHG 700 (ML Astro). Présentation de SUNSCAN aux RCE.
-
2025 : JSol’Ex agréé pour la base BASS2000. Atlas de spectrohéliogrammes de Váradi Nagy et Pietrow. Premier prix SAF de l’innovation pour SUNSCAN.
-
2026 : lancement de SpectroSolHub. Parution du Guide de l’observation solaire avec un spectrohéliographe de Buil et Desnoux.
Influence et bilan
En un peu plus d’un siècle, la frontière entre professionnels et amateurs s’est déplacée. Jusqu’aux années 1990, un amateur capable de bâtir un spectrohéliographe atteignait au mieux les performances d’un observatoire des années 1900-1930. Les instruments amateurs d’aujourd’hui réunissent une optique de précision, des capteurs CMOS rapides et des logiciels ouverts. Ils donnent accès, à faible coût, à des observables (Doppler, magnétogramme, hélium D3, couronne en Fe XIV) autrefois réservées aux grands observatoires solaires.
Cette complémentarité avec la recherche professionnelle a pourtant ses limites. L’atout d’un spectrohéliographe, amateur ou professionnel, est de couvrir d’un coup le disque solaire entier. Son pouvoir de résolution spectrale, en revanche, plafonne autour de R ≈ 30 000, soit un ordre de grandeur en deçà des R > 300 000 requis par la spectroscopie solaire de pointe [4]. Cette finesse est l’apanage de grands instruments spécialisés, qui n’observent qu’un très petit champ à la fois. L’apport amateur se loge donc dans la couverture, spatiale, temporelle et multi-raies, plus que dans la précision spectrale.
Plusieurs ressorts expliquent cette trajectoire. Le matériel est devenu abordable : réseaux répliqués dans les années 1960, webcams puis capteurs CMOS dans les années 2000, impression 3D dans les années 2020. Les logiciels et les protocoles ont circulé librement, de Veio à Defourneau, Buil, Desnoux, Smith et Champeau. La pratique s’est enfin structurée, autour de la plateforme communautaire Astrosurf comme de l’Observatoire de Paris, de la société savante SF2A et de l’association STAROS. Versées chaque jour dans BASS2000, les images amateurs prolongent ainsi la mission de Meudon, à présent à l’échelle de plusieurs continents.
|
Note
|
Note sur les sources. L’histoire récente de la spectrohéliographie amateur n’a fait l’objet que de peu de littérature académique : une partie des sources mobilisées ici provient d’archives communautaires (forums, sites personnels, dépôts logiciels, notes de version). Les antériorités revendiquées (« premier… ») et les chiffres de diffusion reposent largement sur la mémoire de cette communauté et gagneraient à être recoupés avec des sources primaires. |
Remerciements
L’auteur remercie Philippe Rousselle pour son témoignage détaillé sur ses premiers spectrohéliogrammes au détecteur linéaire (Atari 520, CCD Thomson) et sur la filiation Defourneau / Rondi / Poupeau. Il remercie également Jean-Marie Malherbe (Observatoire de Paris) pour ses précisions sur la double conception (formes et vitesses) du spectrohéliographe de Deslandres, sur la reprise des mesures de profils de raies à Meudon en 2017 et sur les limites spectrales des instruments à grand champ, ainsi que Florence Cornu (Observatoire de Paris) pour ses relectures et ses retours sur le protocole SOLAP/BASS2000.
Références
-
[1] A. Rondi et S. Rondi, « Histoire de la spectrohéliographie ».
-
[2] Observatoire de Paris-PSL, « Le spectrohéliographe de Meudon ».
-
[3] Site des observateurs solaires, « 110 ans d’observations solaires à Meudon ».
-
[5] G. E. Hale, « The spectrohelioscope and its work (parts I-IV) », Astrophysical Journal 70 (1929), p. 265 et suiv.
-
[6] K. Fortin, « Towering task: astronomy buffs fight to save shuttered observatory near Pontiac », The Detroit News, 15 janvier 2025.
-
[7] « Spectroheliograph », The History and Science of Total Solar Eclipses.
-
[8] F. J. Sellers, « The spectrohelioscope », Memoirs of the British Astronomical Association 37 (1952).
-
[9] M. A. Ellison, « A spectrohelioscope », Journal of the British Astronomical Association 50 (1940), p. 107.
-
[10] F. N. Veio, « History of spectrohelioscopes by amateurs », 2009.
-
[11] Cloudy Nights forum, « RIP Fred Veio, spectrohelioscope pioneer », 28 mars 2023.
-
[12] F. N. Veio, « A compact spectrohelioscope », Sky & Telescope, janvier 1969.
-
[13] B. G. W. Manning, « A new spectrohelioscope », Journal of the British Astronomical Association 92 (1982), p. 112.
-
[14] F. N. Veio et L. F. Higgins, « The Zeeman effect observed with a spectrohelioscope », Journal of the British Astronomical Association 116, février 2006.
-
[16] P. Rousselle, « Observation du Soleil avec un spectrohéliographe ».
-
[17] D. Defourneau, « Construire un spectrohéliographe amateur », 2010.
-
[18] A. Rondi et S. Rondi, « Magnétogrammes amateurs et historique de la spectrohéliographie ».
-
[19] K. M. Harrison, Imaging Sunlight Using a Digital Spectroheliograph, Springer, 2016, ISBN 978-3-319-24872-1.
-
[20] C. Buil, « Sol’Ex : présentation ».
-
[21] Shelyak Instruments, « Kit optique pour spectrohéliographe Sol’Ex ».
-
[22] C. Buil, « Le projet Sol’Ex / Star’Ex », journées ProAm SF2A 2021.
-
[23] P. Garrigues, « Spectrohéliographe - Sol’Ex ».
-
[24] V. Desnoux, « INTI - INTI Spectroheliography Processing ».
-
[25] J.-M. Malherbe, F. Cornu et I. Bualé, « Solex observations for the BASS2000 database, a collaboration PRO-AM », 2023, arXiv:2305.14804.
-
[26] V. Desnoux, Inti_mosaic, dépôt GitHub.
-
[27] V. Desnoux, « INTI Partner ».
-
[28] D. Smith, « New SHG (spectroheliography) software available now for testing », juillet 2021.
-
[29] D. Smith, « Spectroheliograph (SHG) reconstruction software - Python and Java versions », 2 août 2023.
-
[30] D. Smith, « Release Solex_ser_recon_EN version 4.2.1 Windows exe », 8 août 2023.
-
[31] D. Smith, « How to Build and Use a Spectroheliograph - slides and Zoom call recording », mai 2023.
-
[32] M. Considine, Digital_SHG, dépôt GitHub.
-
[33] C. Champeau, « JSol’Ex - documentation officielle ».
-
[34] C. Champeau, « Stacking and mosaic creation with JSol’Ex 2.0 », 4 janvier 2024.
-
[35] C. Champeau, « Ellerman bombs detection with JSol’Ex 3.2 », 17 mai 2025.
-
[36] C. Champeau, « Mesurer la rotation différentielle solaire avec JSol’Ex », 5 février 2026.
-
[37] C. Champeau, astro4j - notes de version.
-
[38] C. Champeau, « JSol’Ex 4.0.0 est sorti ! », 11 septembre 2025.
-
[39] A. Faryad, A. G. M. Pietrow, M. Verma et C. Denker, « Automatic detection of Ellerman bombs in the H-alpha line », 2025, arXiv:2508.10853.
-
[40] P. Váradi Nagy et A. G. M. Pietrow, « An Atlas of Spectroheliograms from 3641 to 6600 Angstrom », 2025, arXiv:2507.13025.
-
[41] C. Champeau, SpectroSolHub - plateforme communautaire de spectrohéliographie solaire, 2026.
-
[42] T. M. Nguyen, « Introducing MLAstro SHG 700 ».
-
[43] ScopeTrader, « How spectroheliographs work », février 2025.
-
[44] S. Ferier et J. Brunet, SolEx-Motorisation, dépôt GitHub.
-
[45] STAROS Projects, SUNSCAN.
-
[46] STAROS Projects, SUNSCAN.
-
[47] C. Buil, « SUNSCAN - L’observatoire solaire autonome », RCE 2024, 9 novembre 2024.
-
[48] STAROS Projects, SUNSCAN - application mobile officielle.
-
[49] Société astronomique de France, « Prix et médailles », Grand Prix triennal pour l’innovation instrumentale amateur 2025.
-
[50] LIRA - Observatoire de Paris, « Rencontre conviviale avec les amateurs SOL’EX à l’Observatoire de Paris pour célébrer la collaboration SOLAP », 19 mai 2025.
-
[51] C. Buil, J.-M. Malherbe et M. Maksimovic, « Sol’Ex et l’imagerie monochromatique solaire », Photoniques 120 (2023), p. 36-40.
Announcing TamboUI
17 February 2026
|
Note
|
This blog post is co-authored by Cédric Champeau (Micronaut) and Max Rydahl Andersen (Quarkus), and cross-posted on our respective personal blogs. |
Today we are excited to announce TamboUI, an open-source Terminal UI framework for the Java ecosystem!
The terminal is having a renaissance.
AI coding tools live there. Developer workflows are increasingly CLI-first again. Rust has Ratatui. Python has Rich and Textual, Go has Charm, Typescript has OpenTUI. But Java, despite its performance, maturity, and tooling, didn’t have a modern, composable, developer-friendly TUI framework.
We thought that should change.
How it started
TamboUI (pronounced like the french word “tambouille”, slang for "cooking up something" or "makeshift creation") was born a bit by accident: a couple months ago, Cédric was asking about which TUI libraries that tools like Claude Code were using. Max Andersen answered that most likely this was Ratatui, a framework written in Rust. Both thought that it was a bit sad that there was no such library for Java.
A few weeks later, Cédric did an experiment by asking AI (Claude Code) to port Ratatui to Java. The result was fairly impressive, and the beginning of a collaboration that led to the creation of TamboUI. In fact, Max gave you a hint last year that this was going to happen.
That said, TamboUI is not a Ratatui port nor is it a Textual port. We’ve put a lot of effort in going beyond the initial AI generated port. The library was designed with Java developers in mind, inspired by the good things found in other ecosystems’ approach to TUI frameworks. It offers a multi-layer API: from low-level widget primitives (like Ratatui), to a managed TUI layer with event handling, up to a declarative Toolkit DSL that handles the event loop and rendering thread for you—things that Ratatui doesn’t really cover. This brings the power of Ratatui, Textual or Rich to the Java ecosystem, with the Java touch!
Not only that, TamboUI is also GraalVM native compatible! This means that you can compile your Java TUI applications as native binaries, making Java a first class citizen in terminal applications development, with low memory footprints and fast startup!
If you want to give it a try, the easiest is to run our demos using JBang:
jbang demos@tambouiTry it out
At this stage, the APIs are still unstable and subject to change. TamboUI is developed with the mindset of being framework-agnostic and having as few external dependencies as possible. You can choose between several backends like JLine, Aesh or the built-in Panama backend. By choosing the latter, you’ll get the best performance while not depending on any external library.
Whether you want to build:
-
a standalone CLI tool
-
an internal developer tool
-
a DevOps utility
-
add a TUI frontend to existing Java tool
-
an AI agent
-
or something entirely new
Give TamboUI a try and let us know what worked and what could be improved!
Check out the documentation at https://tamboui.dev/docs/main/, join us on Zulip, or browse the source on GitHub. We’d love your feedback and contributions!
Acknowledgments
We would like to thank the following people for their ideas, suggestions and contributions to the creation of first public release of TamboUI (in alphabetical order):
-
Andres Almiray
-
Charles Moulliard
-
Claus Ibsen
-
Graeme Rocher
-
Guillaume LaForge
-
James Cobb
-
Ståle Pedersen
-
Tako Schotanus
and of course to the Ratatui and Textual creators for their inspiration and work.
Max Rydahl Andersen & Cédric Champeau
Mesurer la rotation différentielle solaire avec JSol’Ex
05 February 2026
Tags: solex jsolex solaire astronomie doppler rotation
Une boule de plasma en rotation
L’un des aspects fascinants du Soleil est qu’il ne tourne pas comme un corps solide. Contrairement à la Terre, qui effectue une rotation en 24 heures quelle que soit la latitude, la vitesse de rotation du Soleil varie avec la latitude : l’équateur tourne plus vite que les pôles. Ce phénomène, appelé rotation différentielle, est étudié depuis le 19ème siècle et reste un sujet de recherche important en physique solaire.
Les régions équatoriales du Soleil effectuent une rotation en environ 25 jours, tandis que près des pôles, cela prend environ 35 jours. Cette rotation différentielle joue un rôle clé dans le mécanisme de dynamo solaire qui génère le champ magnétique du Soleil et pilote le cycle solaire de 11 ans.

Dans cet article, je vais expliquer comment j’ai ajouté une fonctionnalité dans JSol’Ex 4.5.0 qui permet aux astronomes amateurs de mesurer cette rotation différentielle directement à partir d’un scan obtenu avec un spectrohéliographe. Une erreur fréquente est de penser que cette mesure n’est pas possible parce que la dispersion spectrale d’un spectrographe comme le Sol’Ex est typiquement d’environ 0.1 à 0.2 Å, c’est-à-dire plus grand que l’échelle de ce que nous essayons de mesurer (2 km/s, soit environ 0.04 Å). En pratique, nous devrons obtenir une précision sub-pixellaire et cet article explique comment y arriver.
L’effet Doppler
Le principe derrière la mesure est simple : l'effet Doppler. Quand une source lumineuse se déplace vers nous, la longueur d’onde est décalée vers le bleu du spectre (blueshift). Quand elle s’éloigne, la longueur d’onde se décale vers le rouge (redshift).
Puisque le Soleil tourne, un limbe se déplace toujours vers nous (le limbe Est) tandis que l’autre s’éloigne (le limbe Ouest). En mesurant le décalage de longueur d’onde d’une raie spectrale aux deux limbes, nous pouvons calculer la vitesse de rotation.

On pourrait se demander ce qu’il en est du mouvement propre de la Terre : nous orbitons autour du Soleil à environ 30 km/s, ce qui est bien plus grand que la vitesse de rotation solaire d’environ 2 km/s que nous essayons de mesurer. Ce mouvement orbital produit effectivement un décalage Doppler de tout le spectre solaire. Cependant, cet effet s’applique de manière égale à tous les points que nous pouvons mesurer : en d’autres termes, puisque tout le spectre est décalé de manière uniforme, tout s’annule. Il en va de même pour toute vitesse radiale du Soleil par rapport à la Terre (qui varie légèrement tout au long de l’année car l’orbite de la Terre est elliptique).
La formule fondamentale reliant le décalage Doppler à la vitesse est :
\[\frac{\Delta\lambda}{\lambda_0} = \frac{v}{c}\]
Où :
-
\(\Delta\lambda\) est le décalage en longueur d’onde (ce qu’on cherche à mesurer)
-
\(\lambda_0\) est la longueur d’onde au repos de la raie spectrale (typiquement la longueur d’onde H-alpha)
-
\(v\) est la vitesse le long de la ligne de visée
-
\(c\) est la vitesse de la lumière (299 792 km/s)
La méthodologie de mesure
Travaux antérieurs
Je ne suis pas la première personne à essayer de faire cette mesure en spectrohéliographie amateur. En 2017, Peter Zetner a expliqué sur CloudyNights comment mesurer la vitesse différentielle en utilisant un spectrohéliographe. Il a expliqué cette méthodologie en profondeur dans le livre Astronomie solaire - Observer, photographier et étudier le Soleil. Sa méthodologie repose sur des mesures utilisant la raie Na D2. mais peut aussi être appliquée sur d’autres raies brillantes incluant la raie Fe I couramment utilisée à 5250.2 Å, et implique de comparer les intensités des pixels, en les moyennant à différentes latitudes. Les résultats sont meilleurs en effectuant plusieurs scans et en moyennant les données. Bien que cela fonctionne, je voulais essayer une méthodologie différente :
-
Utiliser un seul scan : les images Doppler que JSol’Ex ou INTI peuvent produire sont en général très cohérentes et montrent que toutes les données dont nous avons besoin sont déjà présentes
-
Éviter les intensités de pixels : celles-ci sont très sensibles à l’assombrissement centre-bord, aux conditions d’observation (par exemple les nuages, même fins) ou au vignetage (assombrissement des images le long de la fente)
-
Rendre possible l’utilisation de scans H-alpha, non pas parce qu’ils donneraient une valeur précise de la vitesse du plasma de la photosphère, mais parce que c’est la raie la plus largement imagée dans les observations solaires amateurs
Les résultats, bien sûr, dépendront de la raie observée. La méthodologie que je décris ci-dessous est capable de retourner des résultats raisonnables sur plusieurs raies (H-alpha, Na D2. Fe I) mais échouera complètement sur certaines autres (par exemple Ca II K, typiquement parce que la raie est trop large).
Plongeons-nous dans la méthodologie.
|
Note
|
L’implémentation décrite ici a été développée de manière itérative basée sur des observations réelles. Je ne suis pas physicien solaire, juste un ingénieur essayant d’extraire des données significatives des captures de spectrohéliographe. L’algorithme fonctionne raisonnablement bien en pratique mais devrait être validé par rapport à des mesures professionnelles pour toute application scientifique. C’est pourquoi cette fonctionnalité est annoncée comme expérimentale. |
Comparaison des limbes Est-Ouest
La clé pour comprendre la méthodologie est qu’elle repose sur l’analyse et l’ajustement de profils de raies spectrales. Elle nécessite d’extraire les profils de raies spectrales à différents endroits du disque solaire, de préférence près des limbes où les vitesses sont les plus élevées (plus on s’approche du méridien solaire, plus les vitesses sont faibles et donc difficiles à détecter).
La mesure de rotation différentielle extrait les vitesses de rotation solaire en comparant les décalages Doppler entre les points des limbes Est et Ouest à la même latitude héliographique.

Pour chaque latitude (par exemple, 20° Nord), l’algorithme :
-
Sélectionne un point sur le limbe Est
-
Sélectionne le point correspondant sur le limbe Ouest à la même latitude
-
Mesure la position de la raie spectrale à chaque point
-
Calcule la différence : Ouest - Est
Cette approche différentielle a un avantage crucial : elle annule les erreurs systématiques. Tout décalage instrumental, erreur de calibration en longueur d’onde, ou décalage de référence affecte les deux mesures de manière égale et disparaît quand nous prenons la différence.
Cependant, une seule mesure Est-Ouest à chaque latitude n’est pas assez fiable. Les conditions de seeing, l’activité solaire locale, ou les erreurs d’ajustement peuvent corrompre les mesures individuelles. Pour améliorer la précision, JSol’Ex échantillonne plusieurs longitudes à travers la région du limbe (typiquement 14 points de 62° à 88° de longitude) et agrège ces mesures. Cette redondance permet de rejeter les valeurs aberrantes et fournit une estimation d’erreur basée sur la cohérence des mesures.
La vitesse mesurée est alors :
\[v_{measured} = \frac{\Delta\lambda}{\lambda_0} \times \frac{c}{2}\]
Le facteur 2 apparaît parce que nous mesurons la différence entre les limbes s’approchant et s’éloignant.
De la vitesse mesurée à la vitesse équatoriale
La vitesse que nous mesurons dépend de la géométrie : quelle fraction de la vitesse de rotation est projetée le long de notre ligne de visée. À l’équateur et au limbe, nous voyons la vitesse de rotation complète. À des latitudes plus élevées ou plus près du centre du disque, nous n’en voyons qu’une fraction.
Le facteur de correction géométrique est :
\[v_{equatorial} = \frac{v_{measured}}{\cos(\phi) \times \sin(\theta)}\]
Où :
-
\(\phi\) est la latitude héliographique
-
\(\theta\) est la longitude héliographique (0° au centre du disque, ±90° aux limbes)
Trouver le centre de la raie spectrale
La partie la plus difficile de la mesure est de déterminer précisément le centre de la raie d’absorption. Un décalage de seulement 0.01 Å correspond à une vitesse d’environ 0.5 km/s, ce qui est significatif par rapport à la vitesse équatoriale typique d’environ 2 km/s.
JSol’Ex utilise l'ajustement de profil de Voigt pour mesurer le centre de la raie. Le profil de Voigt est la convolution d’un profil gaussien et d’un profil lorentzien, qui modélise précisément la forme des raies d’absorption solaires. La composante gaussienne représente l’élargissement Doppler thermique, tandis que la composante lorentzienne représente l’élargissement naturel et de pression.
Pour chaque point de mesure, l’algorithme :
-
Extrait un profil spectral du fichier SER à la position correspondante
-
Ajuste un profil de Voigt à la raie d’absorption
-
Enregistre la position du centre de raie ajustée
Le paramètre configurable "demi-largeur d’ajustement de Voigt" (par défaut : 2 Å) contrôle quelle proportion des ailes de la raie sont incluses dans l’ajustement.
Systèmes de coordonnées
L’un des aspects les plus délicats de cette implémentation est de transformer correctement les coordonnées que nous manipulons. L’algorithme commence avec les coordonnées héliographiques (où nous voulons mesurer) et les transforme en coordonnées des trames SER originales (où les données spectrales se trouvent).
1. Coordonnées héliographiques (point de départ)
Nous commençons par spécifier des points en coordonnées héliographiques :
-
Latitude : -90° (pôle sud) à +90° (pôle nord)
-
Longitude : 0° au centre du disque, ±90° aux limbes
Cela nécessite deux paramètres solaires calculés à partir de la date d’observation :
-
B0 : La latitude héliographique du centre du disque (varie tout au long de l’année)
-
P : L’angle de position de l’axe de rotation (l’inclinaison du Soleil vu depuis la Terre)
2. Coordonnées image
Les coordonnées héliographiques sont converties en positions de pixels dans l’image reconstruite. Cela implique d’inverser les corrections appliquées pendant la reconstruction :
-
Correction de l’angle P
-
Retournement/rotation
-
Distorsion géométrique
-
Angle d’inclinaison
-
Recadrage
3. Coordonnées du fichier SER (destination)
Finalement, les coordonnées image sont mappées vers le fichier vidéo SER brut :
-
Numéro de trame : Position dans la séquence de scan (dérivée de la coordonnée x)
-
Colonne : Position le long de la fente (dérivée de la coordonnée y)
-
Ligne : Direction spectrale (longueur d’onde)
Ce mapping inverse nous permet d’extraire le profil spectral exact à n’importe quelle position héliographique.
Le pipeline de traitement des données
Les mesures brutes sont bruitées. Pour produire une courbe de rotation propre, JSol’Ex utilise un pipeline de traitement en deux étapes :
Étape 1 : Agrégation en longitude
Comme décrit précédemment, à chaque latitude, plusieurs longitudes sont échantillonnées (typiquement 14 points à travers la région du limbe). Ces mesures sont combinées en utilisant l’une des trois méthodes (la médiane par défaut mais vous pouvez choisir) :
-
Médiane : Robuste aux valeurs aberrantes, utilise la valeur centrale
-
Moyenne : Simple moyenne arithmétique
-
Moyenne pondérée : Les points plus proches du limbe (où le signal Doppler est plus fort) ont un poids plus élevé
L’estimation d’erreur de cette étape représente la cohérence des mesures à travers les longitudes.
Étape 2 : Lissage en latitude
Même après l’agrégation en longitude, les mesures latitude par latitude restent bruitées. Les bins de latitude individuels peuvent encore être affectés par des caractéristiques localisées (taches solaires, facules) ou simplement par la dispersion des mesures.
Puisque nous nous attendons à ce que la rotation solaire varie de manière lisse avec la latitude (suivant les termes \(\sin^2\phi\) et \(\sin^4\phi\) de la loi de rotation différentielle), nous pouvons exploiter cette contrainte physique pour réduire davantage le bruit. JSol’Ex applique un filtre de lissage qui combine les points de latitude voisins dans une fenêtre configurable (par défaut : 5°).
De manière importante, les erreurs de l’étape 1 sont propagées plutôt que recalculées à partir de la dispersion dans la fenêtre de lissage. Cela garantit que les barres d’erreur représentent l’incertitude de mesure, pas les variations physiques de latitude.
Pour l’agrégation médiane :
\[\sigma_{smoothed} = \frac{median(\sigma_i)}{\sqrt{n}}\]
Pour la moyenne :
\[\sigma_{smoothed} = \frac{\sqrt{\sum \sigma_i^2}}{n}\]
Le résultat et la comparaison avec la théorie
La forme standard de la loi de rotation différentielle (aussi connue comme la formule de Faye, même si la formule originale n’incluait pas le 3ème terme) est :
\[\omega(\phi) = A + B \sin^2(\phi) + C \sin^4(\phi)\]
Où :
-
\(\phi\) est la latitude héliographique
-
\(A\) est le taux de rotation équatorial
-
\(B\) et \(C\) contrôlent la diminution de la vitesse avec la latitude
JSol’Ex compare les résultats mesurés avec les coefficients largement utilisés de Snodgrass & Ulrich (1990) :
-
\(A = 14.713\) deg/jour (taux de rotation équatorial)
-
\(B = -2.396\) deg/jour
-
\(C = -1.787\) deg/jour
Cela donne une période de rotation équatoriale d’environ 24.5 jours et une période polaire d’environ 34 jours. Convertie en vitesse linéaire à la surface solaire (rayon ≈ 696 000 km), la vitesse de rotation équatoriale est d’environ 2.0 km/s.
JSol’Ex ajuste également ses propres coefficients A, B, C à partir de vos mesures, permettant une comparaison directe avec les valeurs de référence.
Résultats
Ci-dessous des exemples de profils de rotation différentielle mesurés avec JSol’Ex en utilisant deux raies spectrales différentes. Ces mesures ont été prises à des dates différentes avec des conditions de seeing différentes.
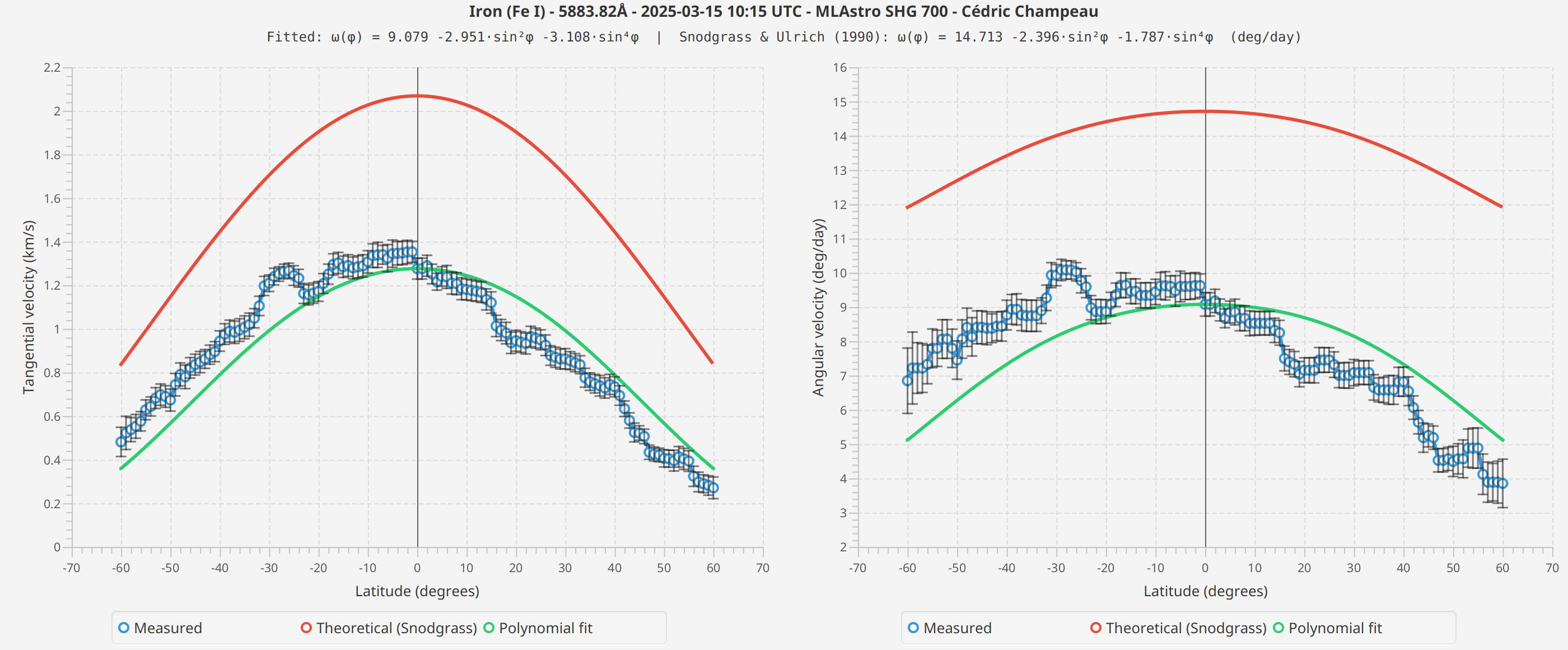
Fe I 5883 Å
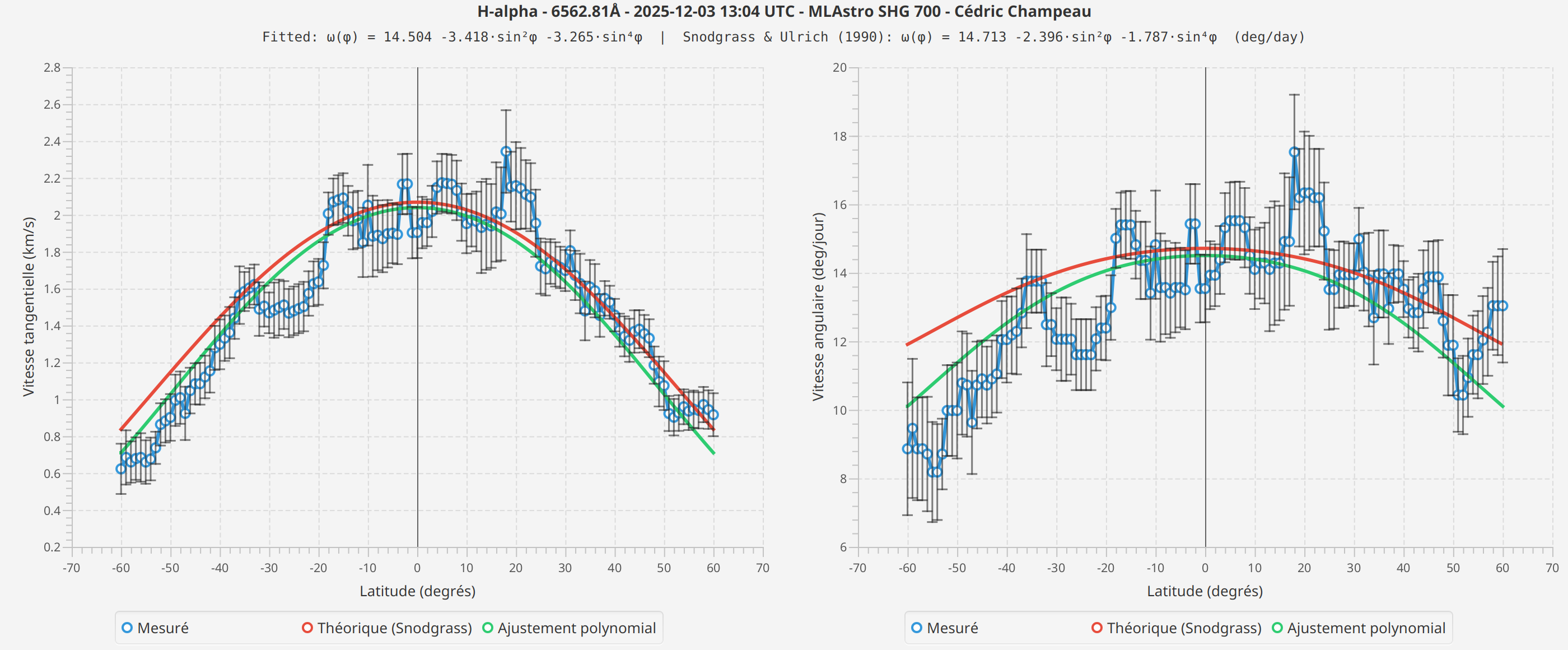
H-alpha
Observations
Les profils mesurés montrent la forme générale attendue : des vitesses plus élevées à l’équateur, diminuant vers les pôles. Les courbes ajustées suivent raisonnablement bien le profil théorique de Snodgrass.
Cependant, j’observe des différences entre les raies spectrales que je ne peux pas entièrement expliquer. Les mesures Fe I montrent des vitesses absolues différentes de H-alpha, et les coefficients ajustés diffèrent entre les scans.
Plusieurs facteurs pourraient contribuer à ces différences :
-
Hauteur de formation : Différentes raies spectrales se forment à différentes hauteurs dans l’atmosphère solaire, et les taux de rotation peuvent varier avec l’altitude (comme suggéré par des recherches récentes de la mission CHASE)
-
Conditions de seeing : Les scans ont été pris à des dates différentes avec des conditions atmosphériques différentes
-
Différences de profil de raie : H-alpha et Fe I ont des largeurs et profondeurs de raie différentes, ce qui peut affecter la précision de l’ajustement de Voigt
-
Effets systématiques : Il peut y avoir des facteurs instrumentaux ou algorithmiques que je n’ai pas identifiés
Je présente ces résultats tels qu’ils sont, sans essayer de tirer des conclusions sur quelle mesure est "correcte" ou ce qui cause les différences observées. Plus de mesures sur différentes dates, raies spectrales et instruments seraient nécessaires pour comprendre ces variations.
Mesurer en pratique
La qualité des résultats dépend fortement du seeing atmosphérique. Un mauvais seeing floute les raies spectrales et rend la détermination précise du centre difficile. Les meilleurs résultats sont obtenus avec d’excellentes conditions de seeing et un instrument bien focalisé. Enfin et surtout, une haute résolution spectrale est préférée, ce qui est normalement le cas avec le Sol’Ex (HR) ou le SHG 700.
Vous pouvez aussi vous demander quelle raie spectrale vous devriez observer. J’ai testé l’algorithme avec Fe I, Na D2 et H-alpha, donnant les résultats ci-dessous. En pratique, les raies d’absorption fortes devraient en théorie produire les meilleurs résultats, car :
-
La profondeur de raie devrait être suffisante pour un ajustement précis
-
Les ailes devraient être bien définies pour l’ajustement de Voigt
-
Le rapport signal sur bruit devrait être élevé
Les raies très larges comme Ca II K sont trop larges pour un ajustement de Voigt précis et produiront des résultats peu fiables. Les raies trop étroites peuvent aussi représenter un défi pour l’ajustement de Voigt mais peuvent fonctionner aussi.
L’impact de la détection de la raie spectrale
Un facteur subtil mais important affectant la précision absolue des mesures est la correction polynomiale utilisée pendant la reconstruction d’image. Comprendre ceci est essentiel pour interpréter correctement vos résultats.
Pendant le traitement du spectrohéliographe, JSol’Ex calcule un polynôme qui fait correspondre chaque position de colonne le long de la fente vers la position de ligne attendue du centre de la raie spectrale. Ce polynôme est calculé à partir de la moyenne des trames SER dans le scan (une heuristique est utilisée pour inclure les trames contenant des données solaires réelles, pas le fond de ciel).
Une telle détection est cruciale car la raie spectrale n’est pas droite à travers la fente en raison de phénomènes optiques : elle constitue ce que nous appelons souvent le "smile". Par conséquent, le centre de raie peut être à la ligne 300 à la colonne 500. mais à la ligne 350 à la colonne 1000. Le polynôme capture cette courbure.
En mesurant les positions de raie relativement au polynôme, nous éliminons efficacement la distorsion optique de nos mesures. Sans cette référence, nous mesurerions la somme de la courbure optique plus le décalage Doppler, rendant impossible l’extraction des minuscules signaux de vitesse que nous recherchons.
Une question clé est : pourquoi ne pouvons-nous pas simplement mesurer la position absolue de la raie spectrale dans chaque trame et calculer les vitesses directement ?
La réponse réside dans la précision requise. Une vitesse de 2 km/s correspond à un décalage de longueur d’onde de seulement ~0.04 Å à H-alpha. Avec une dispersion spectrale typique de 0.1-0.2 Å/pixel, c’est un décalage de seulement 0.2 à 0.4 pixels.
La courbure optique à travers la fente, d’autre part, peut facilement s’étendre sur 10-30 pixels ou plus. Toute tentative de mesurer les positions absolues de raie serait complètement dominée par cette courbure, rendant la détection Doppler impossible.
Le polynôme sert de référence de base. En mesurant comment la position de raie dans chaque trame individuelle dévie du polynôme, nous isolons la composante Doppler de la composante optique. C’est l’idée clé qui rend les mesures de précision sub-pixellaire possibles, avec l’ajustement de Voigt.
Un mot sur les images Doppler
Ceci, d’ailleurs, est aussi une raison pour laquelle les images Doppler sont différentes quand on scanne en AD vs DEC. Parce que c’est une question souvent posée, et qu’il m’a fallu des mois pour comprendre la raison, je pense qu’il vaut la peine de passer un peu de temps à expliquer le phénomène. Je dois cette explication à Jean-François Pittet et Christian Buil, d’une discussion il y a quelques semaines sur la mailing list Sol’Ex.
Scan en AD vs scan en DEC : une différence critique pour les images Doppler
Les spectrohéliographes peuvent scanner le Soleil dans deux directions :
-
Scan en AD (Ascension Droite) : La fente est orientée Nord-Sud, et le scan procède Est-Ouest
-
Scan en DEC (Déclinaison) : La fente est orientée Est-Ouest, et le scan procède Nord-Sud
Ce choix a des implications profondes pour la visibilité Doppler, comme expliqué par Jean-François Pittet sur la mailing list Sol’Ex.
Scan en AD : Doppler visible dans les images
En mode scan AD, chaque trame capture une tranche verticale du Soleil du pôle Nord au pôle Sud. Au cours du scan :
-
Les premières trames capturent le limbe Est (s’approchant, décalé vers le bleu)
-
Les trames du milieu capturent le centre du disque (pas de vitesse radiale)
-
Les dernières trames capturent le limbe Ouest (s’éloignant, décalé vers le rouge)
Quand JSol’Ex calcule le polynôme à partir de la moyenne de toutes les trames, les contributions Est et Ouest s’équilibrent. Le blueshift du limbe Est est annulé par le redshift du limbe Ouest. Le polynôme résultant représente la référence "neutre" : approximativement la position de raie au centre du disque sans décalage Doppler.
En conséquence, quand nous reconstruisons l’image au décalage de pixel 0. les décalages Doppler deviennent visibles comme différences de contraste :
-
Le limbe Est apparaît plus sombre (raie décalée dans la bande passante)
-
Le limbe Ouest apparaît plus clair (raie décalée hors de la bande passante)
C’est pourquoi les images Doppler des scans AD montrent l’asymétrie caractéristique Est-Ouest.
Scan en DEC : Doppler "absorbé" par le polynôme
En mode scan DEC, chaque trame capture une tranche horizontale du Soleil d’Est en Ouest. Voici la différence critique : tous les pixels dans une seule trame voient approximativement le même décalage Doppler.
Par exemple, si la trame actuelle capture la moitié Est du disque :
-
Tous les points dans cette trame s’approchent de nous
-
Tous les points ont un blueshift similaire
Quand JSol’Ex calcule le polynôme à partir de la moyenne de toutes les trames, il ne capture pas seulement la courbure optique : il capture aussi le décalage Doppler moyen à travers le scan. Mais voici le problème : le décalage Doppler varie systématiquement à travers le scan (les trames Est sont décalées vers le bleu, les trames Ouest sont décalées vers le rouge).
Le polynôme "absorbe" effectivement une moyenne pondérée de ces décalages Doppler. Quand nous mesurons ensuite les positions de raie relativement à ce polynôme, une grande partie du signal Doppler a déjà été soustraite. Les images Doppler résultantes ne montreront plus la rotation du soleil (ce qui peut aussi être un avantage, pour d’autres types d’observations).
C’est pourquoi les spectrohéliographes expérimentés préfèrent souvent le scan AD pour le travail Doppler : le signal Doppler est plus visible et plus facile à détecter.
La complication de l’angle P
Il y a une subtilité supplémentaire : l’axe de rotation du Soleil n’est pas perpendiculaire à l’écliptique. L'angle P (angle de position de l’axe de rotation) varie tout au long de l’année d’environ -26° à +26°.
Deux fois par an (vers début juin et début décembre) l’angle P est proche de zéro. À ces moments :
-
Le scan AD est vraiment parallèle à l’équateur solaire
-
Le motif Doppler Est-Ouest s’aligne parfaitement avec la direction de scan
À d’autres moments, quand P est non nul :
-
L’axe de rotation est incliné par rapport à la direction de scan
-
Le motif Doppler est tourné par rapport aux axes de l’image
-
Une partie du signal Doppler "fuit" dans la moyenne polynomiale même en mode AD
C’est une des raisons pour lesquelles les mesures de rotation différentielle peuvent montrer des résultats légèrement différents à différentes périodes de l’année, bien que nous prenions en compte les angles P et B0.
Implications pour les mesures de rotation différentielle
Ceci explique pourquoi le scan AD est essentiel pour les mesures de vitesse différentielle :
En mode AD, les points des limbes Est et Ouest à la même latitude correspondent à la même colonne sur la fente (même position de fente, trames différentes).
La valeur du polynôme à cette colonne est calculée à partir de la moyenne de toutes les trames (limbe Est, centre du disque, et limbe Ouest) donc les décalages Doppler s’annulent dans la moyenne.
Quand nous calculons (Ouest - polynôme) - (Est - polynôme), les termes du polynôme sont identiques et s’annulent, nous laissant avec la vraie différence Doppler Ouest - Est.
En mode DEC, les points des limbes Est et Ouest à la même latitude correspondent aux extrémités opposées de la fente (colonnes différentes, même trame). Le polynôme à la colonne Est est calculé à partir de trames qui voient toutes le limbe Est à cette position, donc le polynôme absorbe le blueshift. De même, le polynôme à la colonne Ouest absorbe le redshift. Quand nous calculons la différence, ces décalages Doppler absorbés ne s’annulent pas : ils se soustraient de notre mesure, réduisant significativement le signal mesuré.
C’est pourquoi, en pratique, les scans DEC ne produisent pas d’images Doppler utilisables ou de mesures de vitesse différentielle fiables.
Conseils de configuration
-
Longitude du limbe (par défaut 75°) : Les mesures plus proches du limbe donnent des signaux Doppler plus forts mais risquent des effets d’assombrissement centre-bord
-
Pas de latitude (par défaut 2°) : Des valeurs plus petites donnent une résolution plus fine mais des temps de traitement plus longs
-
Fenêtre de lissage : Devrait être au moins 2× le pas de latitude pour un lissage efficace
Conclusion
Mesurer la rotation différentielle avec du matériel amateur aurait semblé impossible il y a quelques années seulement. Des pionniers comme Peter Zetner ou Christian Buil nous ont montré la voie. Ce que j’essaie de faire, comme toujours avec JSol’Ex, c’est de rendre ceci accessible à encore plus de personnes au prix de la "magie", c’est-à-dire que certaines personnes partageront très probablement des résultats sans comprendre la science derrière. Je ne suis pas trop inquiet par cela, parce que je suis moi-même passé par là : apprécier la reconstruction d’images SHG, puis comprendre comment ça fonctionne, puis me poser des questions comme "pourquoi est-il même possible de mesurer des vitesses Doppler si petites ?" : c’est une construction intellectuelle qui prend du temps. Nous, membres de la communauté Sol’Ex, pouvons faire mieux, je pense, pour apporter cela aux masses, en partageant nos idées et en écrivant des logiciels comme celui-ci.
Cette fonctionnalité rejoint la liste croissante des capacités scientifiques dans JSol’Ex : détection des bombes d’Ellerman, identification des régions actives, et maintenant mesure de la rotation différentielle. Chacune de celles-ci met des analyses de niveau professionnel à la portée des astronomes amateurs, mais, comme toujours, soyez prudent avec ce que je dis : je ne suis pas un scientifique, juste un ingénieur. Je n’ai aucun doute que j’ai fait des approximations, ou pris des libertés que je n’aurais probablement pas dû prendre.
Bibliographie
Articles scientifiques
-
Howard, R. & Harvey, J. (1970) - Spectroscopic determinations of solar rotation. Sol Phys 12. 23-51
-
Snodgrass, H.B. (1984) - Separation of large-scale photospheric Doppler patterns. Sol Phys 94, 13-31
-
Beck, J.G. (2000) - A comparison of differential rotation measurements. Sol Phys 191, 47-70
-
Corbard, T. et al. (2025) - Rotational radial shear in the low solar photosphere. A&A 702. A93
Measuring Solar Differential Rotation with JSol’Ex
05 February 2026
Tags: solex jsolex solar astronomy doppler rotation
A Rotating Ball of Plasma
One fascinating aspect of the Sun is that it doesn’t rotate like a solid body. Unlike the Earth, which completes one rotation in 24 hours regardless of latitude, the Sun’s rotation rate varies with latitude: the equator rotates faster than the poles. This phenomenon, called differential rotation, has been studied since the 19th century and remains an important research topic in solar physics.
The equatorial regions of the Sun complete a rotation in approximately 25 days, while near the poles, it takes about 35 days. This differential rotation is thought to play a key role in the solar dynamo mechanism that generates the Sun’s magnetic field and drives the 11-year solar cycle.

In this blog post, I will explain how I implemented a feature in JSol’Ex 4.5.0 that allows amateur astronomers to measure this differential rotation directly from their spectroheliograph data. A common mistake is to think that this measurement is not possible because the spectral dispersion of a SHG like the Sol’Ex is typically around 0.1 to 0.2Å, which larger than the scale of what we’re trying to measure (2 km/s, which is about 0.04Å). In fact, what we are trying to measure requires sub-pixel precision and we can achieve that.
The Doppler Effect
The principle behind the measurement is simple: the Doppler effect. When a light source moves towards us, the wavelength is shifted towards the blue end of the spectrum (blueshift). When it moves away, the wavelength shifts towards the red (redshift).
Since the Sun rotates, one limb is always moving towards us (let’s say the East limb) while the other is moving away (the West limb). By measuring the wavelength shift of a spectral line at both limbs, we can calculate the rotation velocity.

One might wonder about the Earth’s own motion: we orbit the Sun at approximately 30 km/s, which is much larger than the ~2 km/s solar rotation velocity we’re trying to measure. This orbital motion does produce a Doppler shift of the entire solar spectrum. However, this affects equally all points we can measure: this is a global shift which affects all measurements equally and cancels out. The same is true for any radial velocity of the Sun relative to the Earth (which varies slightly throughout the year as Earth’s orbit is elliptical).
The fundamental formula relating Doppler shift to velocity is:
\[\frac{\Delta\lambda}{\lambda_0} = \frac{v}{c}\]
Where:
-
\(\Delta\lambda\) is the wavelength shift
-
\(\lambda_0\) is the rest wavelength of the spectral line (typically the H-alpha wavelength)
-
\(v\) is the velocity along the line of sight
-
\(c\) is the speed of light (299,792 km/s)
The Measurement Methodology
Previous Work
I am not the first person to try to make this measurement in amateur spectroheliography. In 2017, Peter Zetner explained on CloudyNights how to measure differential velocity using a spectroheliograph. He explained this methodology in depth in the Solar Astronomy - Observing, imaging and studying the Sun book. His methodology relies on measurements using the Na D2 line, but can also be applied on other bright lines including the commonly used Fe I line at 5250.2 Å, and involves comparing the pixel intensities, by averaging them at different latitudes. The best results are obtained by performing several scans and averaging data. While this works, I wanted to try a different methodology:
-
Use a single scan: the Doppler images that JSol’Ex or INTI can produce are in general very consistent and show that all the data we need is already present
-
Avoid pixel intensities: these are very sensitive to limb darkening, observing conditions (e.g clouds, even if thin) or vignetting (darkening of the images along the slit)
-
Make it possible to use H-alpha scans, not because they would give an accurate value of the velocity of the photosphere plasma, but because that’s the most widely imaged line in amateur solar observations
The results, of course, will depend on the observed line. The methodology that I describe below is capable of returning reasonable results on several lines (H-alpha, Na D2, Fe I) but will completely fail on some others (e.g Ca II K, typically because the line is too wide).
Let’s dive into the methodology.
|
Note
|
The implementation described here was developed iteratively based on real observations. I’m not a solar physicist, just an engineer trying to extract meaningful data from spectroheliograph captures. The algorithm works reasonably well in practice but should be validated against professional measurements for any scientific application. Therefore why it is advertised as experimental. |
East-West Limb Comparison
The key to understanding the methodology is that it relies on spectral line profile analysis and fitting. It requires extracting the spectral line profiles at different locations of the solar disk, preferably near the limbs where the velocities are highest.
The differential rotation measurement extracts solar rotation velocities by comparing Doppler shifts between East and West limb points at the same heliographic latitude.

For each latitude (say, 20° North), the algorithm:
-
Selects a point on the East limb
-
Selects the corresponding point on the West limb at the same latitude
-
Measures the spectral line position at each point
-
Computes the difference: West - East
This differential approach has a crucial advantage: it cancels out systematic errors. Any instrumental offset, wavelength calibration error, or baseline shift affects both measurements equally and disappears when we take the difference.
However, a single East-West measurement at each latitude is not reliable enough. Seeing conditions, local solar activity, or fitting errors can corrupt individual measurements. To improve accuracy, JSol’Ex samples multiple longitudes across the limb region (typically 14 points from 62° to 88° longitude) and aggregates these measurements. This redundancy allows outliers to be rejected and provides an error estimate based on measurement consistency.
The measured velocity is then:
\[v_{measured} = \frac{\Delta\lambda}{\lambda_0} \times \frac{c}{2}\]
The factor of 2 appears because we’re measuring the difference between approaching and receding limbs.
From Measured Velocity to Equatorial Velocity
The velocity we measure depends on the geometry: how much of the rotation velocity is projected along our line of sight. At the equator and at the limb, we see the full rotation velocity. At higher latitudes or closer to disk center, we see only a fraction.
The geometric correction factor is:
\[v_{equatorial} = \frac{v_{measured}}{\cos(\phi) \times \sin(\theta)}\]
Where:
-
\(\phi\) is the heliographic latitude
-
\(\theta\) is the heliographic longitude (0° at disk center, ±90° at the limbs)
Finding the Spectral Line Center
The most challenging part of the measurement is accurately determining the center of the absorption line. A shift of just 0.01 Å corresponds to a velocity of about 0.5 km/s, which is significant compared to the typical equatorial velocity of ~2 km/s.
JSol’Ex uses Voigt profile fitting to measure the line center. The Voigt profile is the convolution of a Gaussian and a Lorentzian profile, which accurately models the shape of solar absorption lines. The Gaussian component represents thermal Doppler broadening, while the Lorentzian component represents natural and pressure broadening.
For each measurement point, the algorithm:
-
Extracts a spectral profile from the SER file at the corresponding position
-
Fits a Voigt profile to the absorption line
-
Records the fitted line center position
The configurable "Voigt fit half-width" parameter (default: 2 Å) controls how much of the line wings are included in the fit.
Coordinate Systems
One of the trickier aspects of this implementation is correctly mapping between the different coordinate systems involved. The algorithm starts with heliographic coordinates (where we want to measure) and maps them back to the original SER frames (where the spectral data lives).
1. Heliographic Coordinates (starting point)
We begin by specifying points in heliographic coordinates:
-
Latitude: -90° (south pole) to +90° (north pole)
-
Longitude: 0° at disk center, ±90° at the limbs
This requires two solar parameters computed from the observation date:
-
B0: The heliographic latitude of the disk center (varies throughout the year)
-
P: The position angle of the rotation axis (the "tilt" of the Sun as seen from Earth)
2. Image Coordinates
The heliographic coordinates are converted to pixel positions in the reconstructed image. This involves reversing the corrections applied during reconstruction:
-
P-angle correction
-
Flip/rotation
-
Geometric distortion
-
Tilt angle
-
Cropping
3. SER File Coordinates (destination)
Finally, the image coordinates are mapped to the raw SER video file:
-
Frame number: Position in the scan sequence (derived from x-coordinate)
-
Column: Position along the slit (derived from y-coordinate)
-
Row: Spectral direction (wavelength)
This reverse mapping allows us to extract the exact spectral profile at any heliographic location.
The Data Processing Pipeline
The raw measurements are noisy. To produce a clean rotation curve, JSol’Ex uses a two-stage processing pipeline:
Stage 1: Longitude Aggregation
As described earlier, at each latitude, multiple longitudes are sampled (typically 14 points across the limb region). These measurements are combined using one of three methods (the default is median but you can choose):
-
Median: Robust to outliers, uses the middle value
-
Average: Simple arithmetic mean
-
Weighted Average: Points closer to the limb (where Doppler signal is stronger) get higher weight
The error estimate from this stage represents the consistency of measurements across longitudes.
Stage 2: Latitude Smoothing
Even after longitude aggregation, the latitude-by-latitude measurements remain noisy. Individual latitude bins can still be affected by localized features (sunspots, faculae) or simply measurement scatter.
Since we expect solar rotation to vary smoothly with latitude (following the \(\sin^2\phi\) and \(\sin^4\phi\) terms of the differential rotation law), we can exploit this physical constraint to reduce noise further. JSol’Ex applies a smoothing filter that combines nearby latitude points within a configurable window (default: 5°).
Importantly, the errors from Stage 1 are propagated rather than recomputed from the spread in the smoothing window. This ensures the error bars represent measurement uncertainty, not physical latitude variations.
For the median aggregation:
\[\sigma_{smoothed} = \frac{median(\sigma_i)}{\sqrt{n}}\]
For the average:
\[\sigma_{smoothed} = \frac{\sqrt{\sum \sigma_i^2}}{n}\]
The Outcome and Comparison with Theory
The standard form of the differential rotation law (also known as the Faye formula, even if the original formula didn’t include the 3rd term) is:
\[\omega(\phi) = A + B \sin^2(\phi) + C \sin^4(\phi)\]
Where:
-
\(\phi\) is the heliographic latitude
-
\(A\) is the equatorial rotation rate
-
\(B\) and \(C\) control the decrease in velocity with latitude
JSol’Ex compares measured results with the widely-used coefficients from Snodgrass & Ulrich (1990):
-
\(A = 14.713\) deg/day (equatorial rotation rate)
-
\(B = -2.396\) deg/day
-
\(C = -1.787\) deg/day
This gives an equatorial rotation period of about 24.5 days and a polar period of about 34 days. Converting to linear velocity at the solar surface (radius ≈ 696,000 km), the equatorial rotation velocity is approximately 2.0 km/s.
JSol’Ex also fits its own A, B, C coefficients from your measurements, allowing direct comparison with the reference values.
Results
Below are example differential rotation profiles measured with JSol’Ex using two different spectral lines. These measurements were taken on different dates with different seeing conditions.
Fe I 5883 Å
H-alpha
Observations
The measured profiles show the expected general shape: higher velocities at the equator, decreasing toward the poles. The fitted curves follow the theoretical Snodgrass profile reasonably well.
However, I observe differences between spectral lines that I cannot fully explain. The Fe I measurements show different absolute velocities than H-alpha, and the fitted coefficients differ between scans.
Several factors could contribute to these differences:
-
Formation height: Different spectral lines form at different heights in the solar atmosphere, and rotation rates may vary with height (as suggested by recent research from the CHASE mission)
-
Seeing conditions: The scans were taken on different dates with different atmospheric conditions
-
Line profile differences: H-alpha and Fe I have different line widths and depths, which may affect the Voigt fitting precision
-
Systematic effects: There may be instrumental or algorithmic factors I haven’t identified
I present these results as they are, without attempting to draw conclusions about which measurement is "correct" or what causes the observed differences. More measurements across different dates, spectral lines, and instruments would be needed to understand these variations.
Measuring in Practice
The quality of results depends heavily on atmospheric seeing. Poor seeing blurs the spectral lines and makes accurate center determination difficult. Best results are obtained with excellent seeing conditions and a well-focused instrument. Last but not least, a high spectral resolution is preferred, which is normally the case with Sol’Ex (HR) or the SHG 700.
You may also wonder which spectral line you should observe. I tested the algorithm with Fe I, Na D2 and H-alpha, giving the results below. In practice, strong absorption lines should in theory produce the best results, because:
-
The line depth should be sufficient for accurate fitting
-
The wings should be well-defined for Voigt fitting
-
The signal-to-noise ratio should be high
Very broad lines like Ca II K are too wide for accurate Voigt fitting and will produce unreliable results. Too narrow lines may also represent a challenge for Voigt fitting but may work too.
The Impact of the Spectral Line Detection
One subtle but important factor affecting the absolute accuracy of the measurements is the polynomial correction used during image reconstruction. Understanding this is essential for interpreting your results correctly.
During spectroheliograph processing, JSol’Ex computes a polynomial that maps each column position along the slit to the expected row position of the spectral line center. This polynomial is computed from the average of SER frames in the scan (a heuristic is used to include frames containing actual solar data, not sky background).
Such a detection is crucial because the spectral line is not straight across the slit due to optical phenomenons: it consistutes what we often call the "smile". Therefore, the line center might be at row 300 at column 500, but at row 350 at column 1000. The polynomial captures this curvature.
By measuring line positions relative to the polynomial, we effectively remove the optical distortion from our measurements. Without this reference, we would be measuring the sum of optical curvature plus Doppler shift, making it impossible to extract the tiny velocity signals we’re after.
A key question is: why can’t we just measure the absolute position of the spectral line in each frame and compute velocities directly?
The answer lies in the precision required. A velocity of 2 km/s corresponds to a wavelength shift of only ~0.04 Å at H-alpha. With a typical spectral dispersion of 0.1-0.2 Å/pixel, this is a shift of only 0.2 to 0.4 pixels.
The optical curvature across the slit, on the other hand, can easily span 10-30 pixels or more. Any attempt to measure absolute line positions would be completely dominated by this curvature, making Doppler detection impossible.
The polynomial serves as our reference baseline. By measuring how the line position in each individual frame deviates from the polynomial, we isolate the Doppler component from the optical component. This is the key insight that makes sub-pixel precision measurements possible, alongside the Voigt fitting.
A Word About Doppler Images
This, by the way, is also a reason why the Doppler images look different when scanning in RA vs DEC. Because this is a question that is often asked, and that it took months for me to understand the reason, I think it’s worth spending a bit of time explaining the phenomenon. I owe this explanation to Jean-François Pittet and Christian Buil, from a discussion weeks ago on the Sol’Ex mailing list.
RA Scanning vs DEC Scanning: A Critical Difference for Doppler Images
Spectroheliographs can scan the Sun in two directions:
-
RA scanning (Right Ascension): The slit is oriented North-South, and the scan proceeds East-West
-
DEC scanning (Declination): The slit is oriented East-West, and the scan proceeds North-South
This choice has profound implications for Doppler visibility, as explained by Jean-François Pittet on the Sol’Ex mailing list.
RA Scanning: Doppler Visible in Images
In RA scanning mode, each frame captures a vertical slice of the Sun from North pole to South pole. Over the course of the scan:
-
Early frames capture the East limb (approaching, blueshifted)
-
Middle frames capture the disk center (no radial velocity)
-
Late frames capture the West limb (receding, redshifted)
When JSol’Ex computes the polynomial from the average of all frames, the East and West contributions balance out. The blueshift from the East limb is canceled by the redshift from the West limb. The resulting polynomial represents the "neutral" baseline: approximately the line position at disk center with no Doppler shift.
As a result, when we reconstruct the image at pixel shift 0, the Doppler shifts become visible as contrast differences:
-
East limb appears darker (line shifted into the passband)
-
West limb appears brighter (line shifted out of the passband)
This is why Doppler images from RA scans show the characteristic East-West asymmetry.
DEC Scanning: Doppler "Absorbed" by the Polynomial
In DEC scanning mode, each frame captures a horizontal slice of the Sun from East to West. Here’s the critical difference: all pixels within a single frame see approximately the same Doppler shift.
For example, if the current frame is capturing the Eastern half of the disk:
-
All points in that frame are approaching us
-
All points have similar blueshift
When JSol’Ex computes the polynomial from the average of all frames, it doesn’t just capture the optical curvature: it also captures the average Doppler shift across the scan. But here’s the problem: the Doppler shift varies systematically across the scan (East frames are blueshifted, West frames are redshifted).
The polynomial effectively "absorbs" a weighted average of these Doppler shifts. When we then measure line positions relative to this polynomial, much of the Doppler signal has already been subtracted out. The resulting Doppler images will no longer show the rotation of the sun (which can also be a benefit, for other kind of observations).
This is why experienced spectroheliographers often prefer RA scanning for Doppler work: the Doppler signal is more visible and easier to detect.
The P-Angle Complication
There’s an additional subtlety: the Sun’s rotation axis is not perpendicular to the ecliptic. The P-angle (position angle of the rotation axis) varies throughout the year from about -26° to +26°.
Only twice per year (around early June and early December) is the P-angle close to zero. At these times:
-
RA scanning is truly parallel to the solar equator
-
The East-West Doppler pattern aligns perfectly with the scan direction
At other times, when P is non-zero:
-
The rotation axis is tilted relative to the scan direction
-
The Doppler pattern is rotated relative to the image axes
-
Some Doppler signal "leaks" into the polynomial average even in RA mode
This is one reason why differential rotation measurements can show slightly different results at different times of year, despite us taking the P and B0 angles into account.
Implications for Differential Rotation Measurements
This explains why RA scanning is essential for differential velocity measurements:
In RA mode, East and West limb points at the same latitude correspond to the same column on the slit (same slit position, different frames).
The polynomial value at that column is computed from the average of all frames (East limb, disk center, and West limb) so the Doppler shifts cancel out in the average.
When we compute (West - polynomial) - (East - polynomial), the polynomial terms are identical and cancel, leaving us with the true Doppler difference West - East.
In DEC mode, East and West limb points at the same latitude correspond to opposite ends of the slit (different columns, same frame). The polynomial at the East column is computed from frames that all see the East limb at that position, so the polynomial absorbs the blueshift. Similarly, the polynomial at the West column absorbs the redshift. When we compute the difference, these absorbed Doppler shifts don’t cancel: they subtract from our measurement, significantly reducing the measured signal.
This is why, in practice, DEC scans do not produce usable Doppler images or reliable differential velocity measurements.
Configuration Tips
-
Limb longitude (default 75°): Measurements closer to the limb give stronger Doppler signals but risk limb darkening effects
-
Latitude step (default 2°): Smaller values give finer resolution but longer processing times
-
Smoothing window: Should be at least 2× the latitude step for effective smoothing
Conclusion
Measuring differential rotation with amateur equipment would have seemed impossible just a few years ago. Pioneers like Peter Zetner or Christian Buil showed us the path. What I’m trying to do, as always with JSol’Ex, is to make this accessible to even more people at the cost of "magic", which is that some people will very likely share results without understanding the science behind it. I’m not too concerned by this, as I, myself, have been going this way: enjoying SHG image reconstruction, then figuring out how it works, then asking myself questions like "why is it even possible that we measure Doppler velocities so small?": this is an intellectual construct that takes time and we can do better, I think, at brining this to the masses, sharing our insights.
This feature joins the growing list of scientific capabilities in JSol’Ex: Ellerman bomb detection, active region identification, and now differential rotation measurement. Each of these brings professional-level analysis within reach of amateur astronomers, but, as always, be cautious with what I’m saying: I’m not a scientist, just an engineer. I have no doubts that I made approximations, or took liberties that I should probably not have taken.
However, I do think that this brings value to the ecosystem.
Bibliography
Scientific Papers
-
Howard, R. & Harvey, J. (1970) - Spectroscopic determinations of solar rotation. Sol Phys 12, 23-51
-
Snodgrass, H.B. (1984) - Separation of large-scale photospheric Doppler patterns. Sol Phys 94, 13-31
-
Beck, J.G. (2000) - A comparison of differential rotation measurements. Sol Phys 191, 47-70
-
Corbard, T. et al. (2025) - Rotational radial shear in the low solar photosphere. A&A 702, A93
Older posts are available in the archive.
